很多人都知道,网站的信息采集非常的重要,可以从别的网站里的数据采集过来给自己的网站使用,所以就需要用到QueryList插件了,下面就系统的讲一下在thinkphp6下是如何使用QueryList的。
首先是下载QueryList的文件,存放到extend/Caiji里。
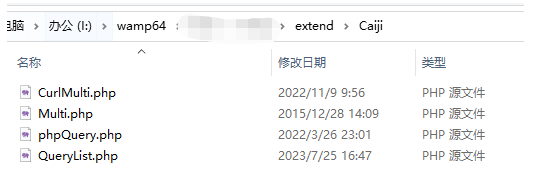
然后是引入文件,如下图所示:
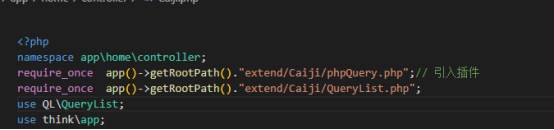
这里需要提一下,引入的文件必须在namespace app\home\controller的下面,否则会程序会报错,引入的代码:
require_once app()->getRootPath()."extend/Caiji/phpQuery.php";// 引入插件
require_once app()->getRootPath()."extend/Caiji/QueryList.php";
use QL\QueryList;
app()->getRootPath()是指引入文件根路径,例如这里是I:/wamp64/www/。
现在来讲使用,其实采集网站数据除非就是打开要采集网站的指定的URL,打开后页面后,匹配相关的标签,得到我们要采集的数据的一个数组,然后对数组进行一系列的处理后,得到我们想到的数据,然后将这些数据写入到数据库表里,就基本完成了。
例如我们打开某个页面,代码如下:
$html = '某个网站的URL';
$rules = [
'title'=>['.article__title','text'],
'lay'=>['.meta-info-list li:eq(2) a','text'],
'lay2'=>['.meta-info-list li:eq(3) a','text'],
'content'=>['.article-content>.content','html'],
];
$data_list = QueryList::Query($html,$rules)->data;
其中title是新闻的标题,如下图所示,这里我们用text方式获取.article__title里的纯文本就行

还有lay和lay2是获取文章的作者,lay是每指.meta-info-list 的第二个li的纯文本text,lay2是.meta-info-list第三个li的text,如下图所示:

content是指新闻的具体内容了,处理数据也是整个最复杂的,这里包括去除一些不需要的内容,获取远程的图片地址,并下载图片到本地上等都需要在此操作的,content获取的是.article-content>.content的html,即带有html属性标签的内容。

获取这些内容后,我们先删除<noscript></noscript>里的内容,如下图所示:

$content = preg_replace('#<noscript[^>]*?[^>]*>(.*?)</noscript>#is', '', $content);使用该正则表达式即可删除<noscript></noscript>和里面的内容。
由于内容里存在图片,如下图所示:
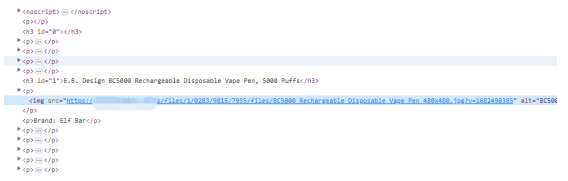
所以我们还要对content进行筛选,得到图片的数组,代码如下:
$rules2 =[
'picture_list'=>['img','src']
];
$data2 = QueryList::Query($content,$rules2)->data;//获得图片的一个二维数组,然后再循环图片,下载图片保存到本地上。
处理以上事情后,就可以将处理后的数据写入到数据表中了,采集也就完成了。




